Over the last year, we’ve seen explosive interest in agentic AI systems built with LLM-powered components that can reason, plan, call tools, and coordinate with other agents. But if you’ve actually tried to build a multi-agent workflow, whether for network automation, observability, or network incident response, you’ve probably run into one glaring problem – all agents don’t speak the same language.
In very simple terms, an agent is software that can perceive its environment in some way, plan accordingly, take some sort of action, and perhaps even learn. One vendor’s “agent” is a Python process that reads JSON. Another is a hosted proprietary service. A third is a LangChain agent running tools locally. Each expects different inputs, different formats, different context handling, and different connection methods. Getting them to talk to each other requires duct tape, wrappers, and a bunch of custom glue code.
That’s the problem the Agent2Agent (A2A) protocol was created to solve. Proposed by Google in the spring of 2025, A2A provides a standard, open way for agents to discover each other, communicate, collaborate, exchange context, and complete tasks together, regardless of framework, vendor, or environment. It’s vendor-neutral, built on open web standards, and designed for real-world enterprise use.
And for network engineering, where we’re starting to see new automation workflows depend on AI-driven troubleshooting, multi-step automations, and cross-domain reasoning, A2A helps get us to an entirely new level of automation.
Why A2A Was Created
Before A2A, multi-agent systems had several problems.
First, there was no standard communication model. Each agent exposed its capabilities in its own way, which meant developers had to write point-to-point integrations. And as the actual A2A spec notes, this made systems brittle, slower to build, and difficult to scale.
Second, agents needed to be wrapped as “tools.” Because there was no unified protocol, developers often wrapped agents inside other agent frameworks which reduced their autonomy and limited their functionality. A2A removes this by letting agents communicate natively as peers.
Third, there was a lack of discoverability. A “consuming” agent had no standardized way to learn what another agent could do. A2A introduces a concept called the Agent Card, which is a machine-readable metadata document describing skills, capabilities, authentication method, and endpoint URL.
Fourth, there was no consistent task handling. Some agents returned raw text, while others returned JSON. Some provided task IDs for long-running jobs, but others didn’t. A2A provides a standardized structure by introducing a model for:
- Messages
- Tasks
- Artifacts
- Status updates
- Streaming outputs
- Asynchronous completions (push notifications)
Last, security was ad hoc. Because agents were stitched together manually, there was no consistent approach to authentication, authorization, or TLS. A2A enables enterprise-grade security patterns using standard web practices (TLS, OAuth2, bearer tokens) and moves identity to the HTTP layer.
All of this makes A2A a protocol designed not just for tech enthusiasts or PoCs (or should I say neverending PoCs 😀), but for real enterprise environments.
How A2A Works
A2A consists of three main components:
- The Agent Card
- Messages and Tasks
- Transport and Connectivity
The Agent Card
Every A2A-enabled agent publishes a JSON description of itself used for capability discovery and usually includes:
- Identity
- Endpoint
- Supported input/output types
- Skills (the tasks it knows how to perform)
- Authentication requirements
- Supported extensions
- Streaming capability
- Push-notification capability
Below is a snippet of code for the A2A agent card. Notice that for capabilities, this agent card defines traceroute and ping.
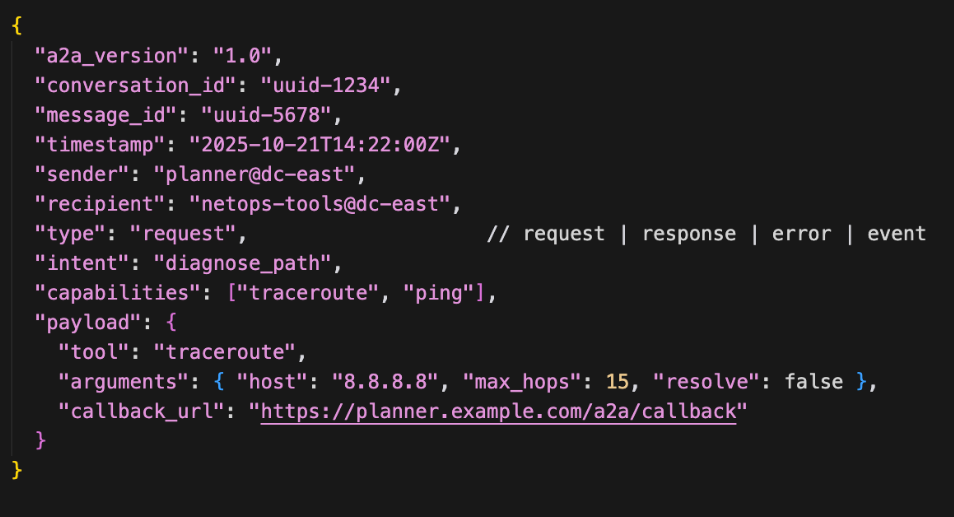
The Agent Card is used for discovery, either via a well-known URI, a central registry, or direct configuration (which seems to be common in the enterprises I’ve worked with experimenting and running agent systems). The result is that agents can find each other and learn each other’s capabilities automatically. There are several components:
- Client agent: formulates and communicates tasks (actions, requests for info, etc)
- Remote agent: acts on the tasks from Clients
- Capability discovery: Agents advertise capabilities using an “Agent Card” in JSON format, allowing the client agent to identify the best agent that can perform a task
- Task management: Communication between a client and remote agent is oriented towards task completion, in which agents work to fulfill end-user requests within a lifecycle. The output of a task is known as an “artifact.”
Capabilities are described in the agent card which means descriptions are essential for advertising capabilities correctly. Notice in the image below that we include a simple description along with an input and output schema. The Description can be more explicit to make sure it’s clear what the agent is capable of.

The actual flow is between the client and the remote agent. If you squint hard enough, A2A can feel DNS-like in that both help distributed systems discover and interact with each other without hardcoding relationships. The similarity stops pretty quickly, but the analogy works from a very high level. Below is a graphic of the A2A communication flow.
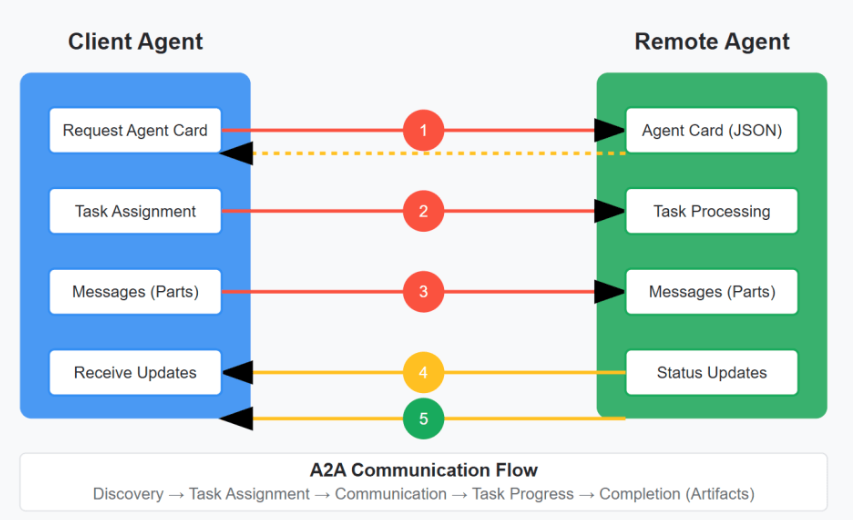
Messages and Tasks
A2A defines two fundamental communication objects, messages and tasks.
Messages are used for short, stateless interactions, and tasks are used for long-running or complex operations that need state management, multi-step processing, intermediate updates, and human-in-the-loop requirements. Think of it as a structured payload that’s sent from one agent to another containing data, instructions, context, or results.
A message typically contains a sender ID, recipient ID, timestamp, content (structured JSON), and a correlation ID. In networking terms, a message is like an RPC call message that’s atomic and stateless on its own.
A task has a well-defined lifecycle (submitted, working, input-required, completed/failed) and the artifacts (completed task outputs) they produce can’t be modified, which ensures traceability. Think of a task as “do this thing”, which in NetOps might be “analyze why site A can’t reach application B”, or “validate prechecks for BGP peer turn-up.”
A task has intent, may span multiple messages, and has a lifecycle state. And in terms of network operations, this model is extremely important because many workflows we use in typical NetOps are long-running. Think of complex root cause analysis and remediation steps that call on multiple network data sources, multiple tools like a RAG function, SQL query generator, ML model, traceroute function, and so on, and require very precise tracking.
Transport and Connectivity
A2A typically operates over HTTPS and supports RPC-style interactions such as:
- HTTPS for transport
- JSON-RPC or gRPC for operations
- SSE for streaming
- Webhooks for asynchronous notifications
That makes A2A compatible with typical enterprise networks behind a firewall, existing API gateways, service meshes, and even iIdentity providers. In other words, A2A basically fits the enterprise environment rather than shoehorning it into the enterprise network ecosystem.
Failure Modes
There are several failure scenarios to consider as well. An agent might be completely unavailable, whether planned or unplanned. Sometimes tasks only partially complete and then stall. Sometimes the agent works fine, but the specific MCP server or downstream tool needed for the task is unavailable.
In an A2A environment, failure is treated as an expected condition rather than an exception. This is different than a simple request–response systems where a failed step often causes the entire workflow to collapse. Instead, A2A is built around the concept of tasks that have lifecycle states. That means a task isn’t a single interaction but instead is a unit of work that persists across multiple interactions and agents. This persistence is what allows the system to handle unavailable agents or incomplete steps without losing track of progress.
When an agent becomes unavailable, the task itself doesn’t disappear. Because the task maintains state, such as pending, running, waiting, completed, or failed, the system can recognize that progress has stalled and figure out why.
For example, if an RCA task retrieves telemetry and configuration data successfully but can’t run an active network test because the testing agent is offline, the task can move into a waiting state rather than failing outright. This preserves the work already completed and keeps the workflow recoverable.
A2A systems also assume that partial completion is normal in distributed environments. Instead of requiring every step to succeed in sequence, they allow intermediate results to accumulate while waiting for dependencies to resolve. This is especially important in network operations, where dependencies such as telemetry sources, testing systems, or inventory services may not always be available at the same time.
And very importantly, A2A systems maintain an audit trail of what was attempted, what succeeded, and what failed. This is extremely valuable for post-incident analysis and operational governance.
Observability for AI Agents
Observability for AI agents, especially in NetOps, is about making their behavior as transparent and diagnosable as possible. There are several mechanisms in place for this.
Task tracing means you can follow an agent’s work from start to finish. When a task was created, which agents participated, what steps were taken, and how long each stage took. This gives engineers visibility into workflow execution, similar to tracing a service request through a distributed system.
Message lineage tracks how information moved between agents. It shows which agent requested what data, which responses were received, and how context evolved over time. In network terms, it’s similar to understanding packet flow but applied to decision-making inputs.
Decision explainability ensures that when an agent proposes a diagnosis or action, you can see why. What data did it rely on? What changes influenced its conclusion? Which assumptions were made? This is very important for trust, governance, and of course for safe automation.
Lastly, task ownership is important for stall detection and escalation.
Using A2A in Network Operations
So how does A2A help network engineers?
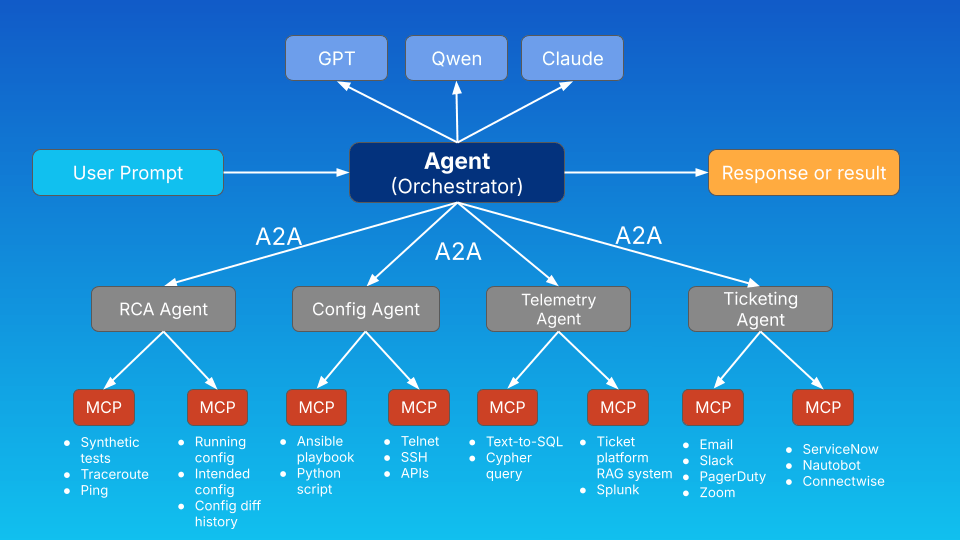
NetOps in a more complex environment would involve multiple specialized AI agents, each performing a piece of a much larger operational activity. In the diagram below, notice that an orchestrator agent communicates via A2A to multiple other agents each specializing in their own capabilities. This can also be designed as a system of agent peers rather than with an orchestrator or “super-agent.”
There’s room to argue over what specific capabilities an RCA agent should have over a telemetry agent, and so on, but the point is that we can create a resilient, functional, distributed AI system this way.
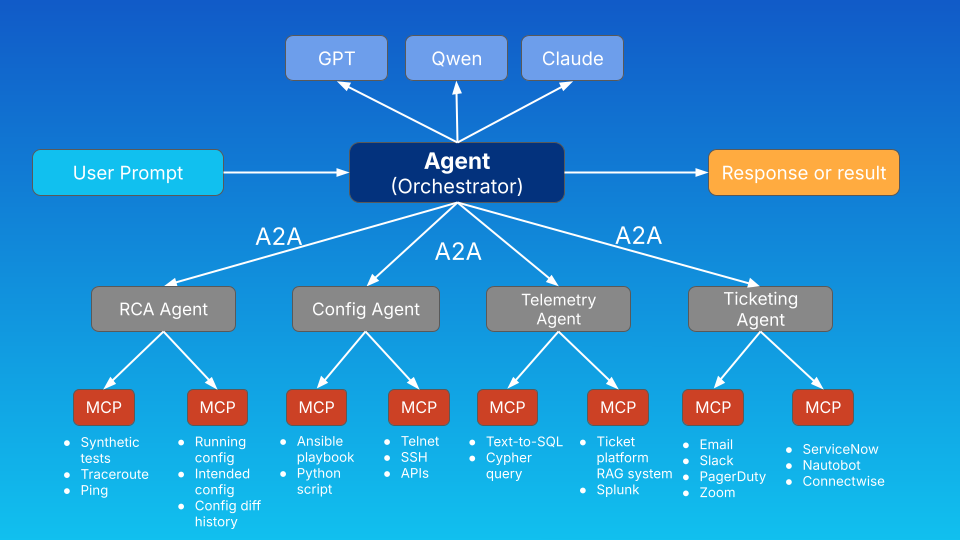
In my example, the orchestrator agent has access to multiple LLMs which act as the “brain” of the system interpreting user prompts, agent card descriptions, and results. In reality, each additional remote agent would also have access to at least one but likely several LLMs as well.
Of course this comes down to a design tradeoff, because though it may be advisable to use the same LLMs for all agents to maintain a level of predictability and consistency (and to minimize licensing headaches), model diversity can also improve reasoning robustness.
I’ve been working in a variety of larger network environments recently, and here are a few examples of what I think would be useful in the real-world.
In my breakdown below, notice that each agent is focused on a specific task, which in reality could be a collection of different tools and workflows, but nevertheless a single conceptual task. There are many benefits to splitting up tasks among multiple agents like being able to upgrade one workflow while leaving others intact, more granular control over access controls, a modular approach to tracing and visibility, and so on.
The likelihood is that you’d start with one agent working with multiple tools or multiple MCP servers, and in time deploy additional functionality in the form of more specialized agents.
Telemetry Agent
First, there’s the telemetry agent. Because of the last few years I’ve spent in observability, this is both top of mind for me but also a great first step in creating your own agent system.
A network telemetry agent would be focused on and have access to telemetry data like device metrics, flow logs, various metadata, your network SoT, IPAM, etc, and the query tools to access that data.
A pure telemetry agent is just that – a way to query telemetry data and not necessarily do much else. This is a great way to keep functionality constrained so that the agent performs only read-only, specialized queries that a NetOps team can build over time to include more data types and sources.
Documentation Agent
A documentation agent would be focused on the workflows involved with searching unstructured text data such as vendor docs, ticketing systems, TAC phone call transcripts, and so on. This would probably be a hybrid RAG system (or systems) which the agent utilizes to answer questions from a KB, correlate information embedded in threat feeds or CVE reports, or perhaps identify trends among all the tickets that came in this year.
Configuration Agent
A configuration agent would specialize in actual device configuration. This kind of agent would need access to syntax knowledge, change management systems, deployment scripts, and programmatic access to network devices.
A config agent starts to get more complex because we need to consider how to add a human-in-the-loop to approve config pushes, rollback procedures, how to identify and fix config drift, strict access controls, logging, and so on.
Topology Agent
A topology agent is an interesting one, and I’ve seen this only once so far. Basically, it’s an agent that understands network structure at the dataplane level, possibly built on a network model that looks at LLDP/CDP relationships, path tracing, metadata, and more.
A topology agent can be a real-time (or near real-time) foundation for a digital twin that other agents can interact with to understand network data that isn’t traffic telemetry. That could be path dependencies for an application, understanding routing adjacencies such as what backup routes exist if the primary becomes unavailable, etc. The topology agent isn’t itself the digital twin, but it would support twin modeling.
Root Cause Analysis Agent
Once we have workflows (or more likely multiple agents) in place to gather and query telemetry, search network and vendor documentation, and perform real-time tests like path traces or ad-hoc synthetic tests, a RCA agent can compile and consider many factors to then come to a conclusion as to the root cause of an incident.
A RCA agent is heavily dependent on multiple underlying workflows, some of which likely very complex on their own, and in reality would be an orchestrator agent handling quite a bit of decision-making grounded in the ability of an LLM to understand the various data, the query itself, and the nature of the incident.
Ticketing Agent
A ticketing agent is a dedicated agent specializing in interacting with human workflow systems. This is something I’m seeing more of lately as folks are reluctant to have one agent handle gathering telemetry, pushing config, updating tickets, and especially touching sources of truth.
The ticketing agent has tools available to interact with these systems after another agent completes a task requiring an update. This adds a layer of complexity for sure, but it adds more granular control and visibility, both of which are absolutely necessary in a production network environment.
There are other specialized agents I’m starting to see people experiment with, but the above give us a good starting point with what’s starting to move from PoC to production in the industry right now. The idea is that with A2A, these independent agents can work together seamlessly, perhaps with a single (fault tolerant) orchestrator agent.
Real-World Example
The real-world examples are pretty much limitless. It really depends on how complex a system you want to build, what data is available, what your needs are, and what budgets and staff resources you have to actually build a multi-agent system with A2A.
Here’s one example.
Diagnosing High Interface Utilization
Imagine an alert fires for high utilization on a core router interface. In an A2A-enabled environment, the workflow might look like this:
Step 1: The RCA Agent receives the alert
It determines it needs additional context and sends a message to the Telemetry Agent: in natural language, “Provide 6 hours of bitrate data for device XYZ interface Gi0/0.”
Because A2A standardizes messages, the RCA Agent doesn’t need to know the various tools the Telemetry Agent uses, and it doesn’t need to know its internal implementation.
Step 2: The Telemetry Agent returns a task
The Telemetry Agent interprets the request from the RCA Agent and access various tools via MCP such as database queries or metric lookups. It completes the task and returns flow breakdowns, a report of packet drops, metrics around latency spikes, or perhaps time series chart data.
Step 3: The RCA Agent interfaces with the Ticketing Agent
The RCA Agent then interfaces with the Ticketing Agent. The Ticketing Agent generates a trouble ticket in ServiceNow, identifies customer dependencies, sends a Slack message in the appropriate channel, perhaps updates a NOC dashboard, and any other necessary documentation or alerting activities.
Step 4: RCA Agent requests topology context
Next, the RCA Agent queries the Topology Agent using A2A to understand adjacent devices via LLDP/CDP, path dependencies, and routing adjacency changes. This helps determine the scope and severity of the incident including important information for potential remediations.
Step 5: RCA Agent aggregates findings
Then, the RCA Agent uses the A2A model for Artifacts to store outputs which in this case are the flow reports, time series graphs, log data, topology information, and so on.
Step 6: Configuration Agent produces remediation
The RCA Agent passes its findings to a Configuration Agent, which generates the actual traffic engineering change which could be BGP policy adjustments, QoS modifications, or maybe even a recommendation to do nothing.
Step 7: Change Control Agent handles workflow
Before pushing any changes, the Configuration Agent uses A2A to talk to the Ticketing Agent to update the ticket, make changes to severity, and explicitly list the recommended remediation and get human approval before proceeding.
All of this is possible because A2A provides task tracking, agent discoverability, multi-step interaction, and secure, structured communication. Without A2A, this workflow requires custom glue code between every component.
A2A and MCP Together
The A2A/MCP relationship is very important to understand.
A2A is all about agent-to-agent communication, like its name suggests. MCP, on the other hand, is about agent-to-tool communication. MCP is how agents call tools like NetFlow database queries, CLI command runners, SNMP polling functions, configuration generators, cloud APIs, and so on. A2A is how agents delegate tasks to other agents, which in practice means A2A is horizontal because agents collaborate across domains and MCP is usually more vertical in that agents access their internal tools.
Why A2A Matters for the Future of NetOps
Network operations is becoming more distributed, more automated, more cross-domain, and in recent days more AI-driven. We don’t really see that much of the “one monolithic network automation platform,” especially when you consider the sum total of network-adjacent platforms relevant to modern NetOps, namely, network sources of truth, observability platforms, digital twins, and so on.
Instead, we’re entering a world where small, specialized agents each perform a task well, agents negotiate, plan, and collaborate, AI becomes the orchestrator, and humans step in only when needed. A2A is the protocol layer that makes this ecosystem possible because it provides a shared language, a predictable communication model, strong task semantics, and the ability to scale automation without brittle integrations. And the idea is that this translates to faster troubleshooting, safer changes, fewer outages, and more intelligent automation.
A2A is the connective tissue that lets agentic systems work together in a way that’s both structured and flexible. For network engineering and operations, it creates the foundation for next-generation automation that’s distributed, collaborative, AI-driven, and fundamentally interoperable.
Thanks,
Phil


Great walkthrough, Phil. The A2A + MCP separation is the right architecture — horizontal agent collaboration plus vertical tool access. One piece I think is missing from the stack: observation verification. In your Step 2, how does the RCA Agent know the Telemetry Agent’s data is real? I ran into this firsthand building a multi-vendor AI ops platform. The AI fabricated three firewall policies that didn’t exist on my FortiGate — among a lot of other data when it wasn’t presented with expected output. It guessed the next most plausible response, which meant hallucinating perfectly formatted, convincing output to the user. Passed every sanity check. Just weren’t real. I’m building a protocol layer (VIRP — Verified Infrastructure Response Protocol) that sits at the MCP boundary and cryptographically signs device observations so agents can prove their data came from the actual device, not from hallucination. The way I think about it: A2A = agent-to-agent, MCP = agent-to-tool, VIRP = tool-to-truth. Would love to compare notes — our work is complementary.
LikeLike
That’s a great point! I think the issue will be more on the interpretation side than the retrieval of metrics side so long as we take certain precautions. One thing is that data that’s stored in the artifact has appropriate source metadata like source of the telemetry, the query that was used, timestamp, etc). Another idea would be to not allow the RCA agent to advance to diagnosis until the necessary artifacts exist in the first place.
And one thing that I’m seeing folks do right now is make sure that any factual statement returned by the system has to reference the actual source information in some way, whether it’s the artifact or just a list of sources. And if a result is generated without the sources, the task can’t proceed and alerts a person. That means you’d need to add a human-in-the-loop as a check.
The steps I put in the blog were pretty high level to help folks get an understanding of a basic workflow, but verification gates at specific points would definitely be a good idea.
LikeLike