Over the past decade, Clos-based leaf-spine architectures have become the default design for data center networking. They deliver predictable latency, horizontal scalability, and clean integration with BGP EVPN/VXLAN overlays. For most enterprise and cloud workloads, they’re still the right architecture.
But large-scale AI training, particularly distributed training of large language models, has exposed the limits of a purely general-purpose network design. This isn’t because Clos is fundamentally flawed, but because the assumptions Clos designs make about traffic distribution no longer hold for certain workloads.
What we’re seeing now is not a replacement of Clos, but a shift toward workload-aligned network design where topology, traffic patterns, and application behavior are tightly coupled. Rail-optimized architectures are one of the clearest recent examples of that shift.
The Mismatch with Clos Architectures
Clos fabrics are built on a simple idea that any endpoint should be able to communicate with any other endpoint with roughly equal cost, and traffic should distribute evenly across the fabric.
That assumption drives ECMP-based load balancing, symmetric bandwidth provisioning, and statistical multiplexing across many flows, or in other words, the idea that if we have many independent flows, the randomness of hashing will, over time, spread traffic evenly across all available paths.
This works extremely well for microservices, east-west traffic, and other bursty, short-lived flows.
Modern distributed AI training relies on collective communication primitives such as AllReduce, AllGather, and ReduceScatter. These operations involve coordinated communication across many GPUs but also occur in synchronized phases. They generate large, long-lived “elephant” flows and follow predictable communication patterns (e.g., rings, trees). In practice, this creates two key characteristics.
First, GPUs are typically organized into tightly coupled groups (within nodes, racks, or pods), in which intra-group bandwidth requirements are extremely high and inter-group communication is more limited and structured. Each GPU worker in a distributed job is assigned a logical identifier, or rank, which defines how it participates in collective communication. Ranks are how distributed systems coordinate and define communication patterns across GPUs.
In the image below, notice how GPUs within a node have a local communication mechanism. This intra-node topology matters because a rail design often assumes that high-bandwidth communication stays local within the node (via NVLink/NVSwitch/PCIe), while inter-node communication is mapped onto network rails.
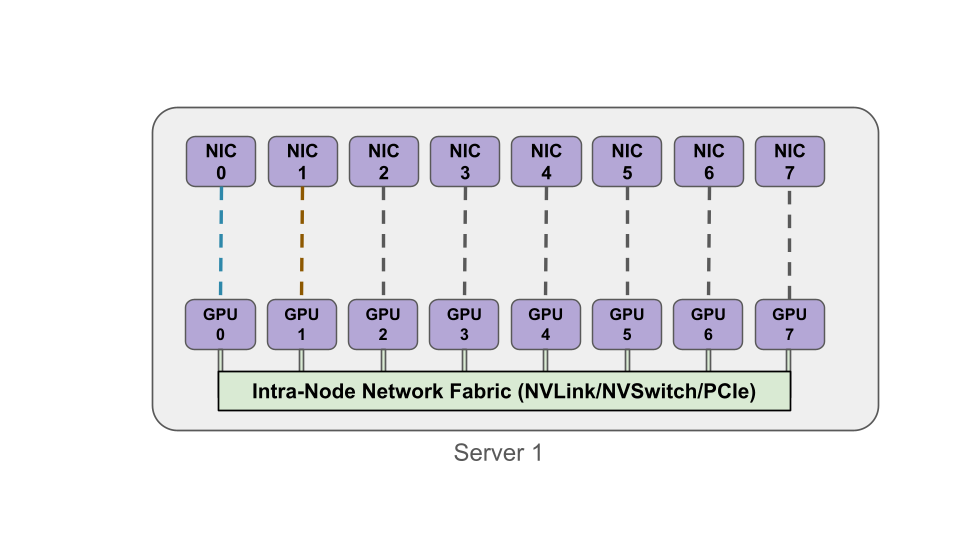
Second, since network communication isn’t arbitrary, it follows the structure of the collective algorithm such as ring-based AllReduce, hierarchical reduction trees, and various pipeline stages across GPU groups.
What this means is that the assumption that traffic will naturally spread evenly across all available paths is not valid for AI workloads.
The Problem with Unconstrained ECMP
Traditional ECMP (without congestion awareness) hashes flows across equal-cost paths based on header fields. In other words, ECMP doesn’t “think” about traffic. For AI workloads, this creates several issues:
- Flow pinning: large flows are mapped to a single path
- Load imbalance: some links become saturated while others remain underutilized
- Incast and congestion: synchronized communication amplifies buffer pressure
- RDMA sensitivity: RoCEv2 environments introduce PFC and ECN interactions, increasing the risk of head-of-line blocking and congestion spreading
Modern fabrics sometimes incorporate adaptive routing or flowlet switching, but even these mechanisms operate on reactive signals, not workload intent. What’s missing is alignment between how the application communicates and how the network forwards traffic.
Rail-optimized designs aren’t primarily about increasing raw bandwidth. They’re about eliminating variability. In AI training, predictability matters more than peak throughput because performance issues from synchronization completely dominate job completion time.
Rail-Optimized Architecture
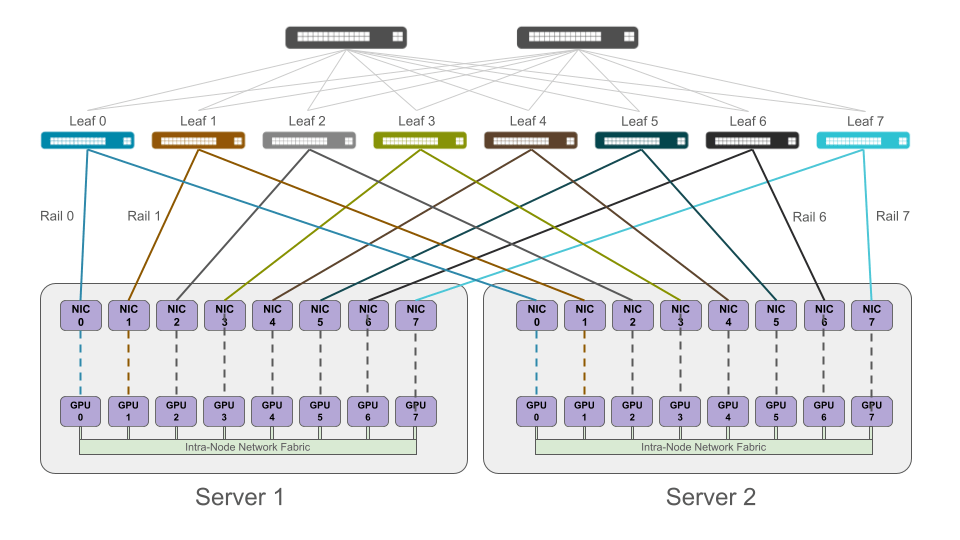
A rail-optimized network addresses this by introducing deterministic structure into the fabric. At a high level, each GPU (or its associated NIC/DPU) is assigned to a specific “rail.”
A rail represents a logically (and sometimes physically) isolated network path, and communication between GPUs is mapped to these rails, rather than randomly distributed. In practical terms, NIC 0 on every server maps to Rail 0, NIC 1 maps to Rail 1, and so on. In practice, this isn’t about isolation for its own sake – it’s about limiting variability. Rails restrict where traffic can go, which is exactly what ECMP lacks for these types of workloads.
We end up with parallel network planes, each carrying a defined subset of traffic. In the image below where rails are color coded for easier visualization, notice how NIC 0 on both Servers 1 and 2 connect to Leaf 0 and create a rail. Each rail aligns the physical network (rails) with the logical rank communication patterns used in the distributed training job.
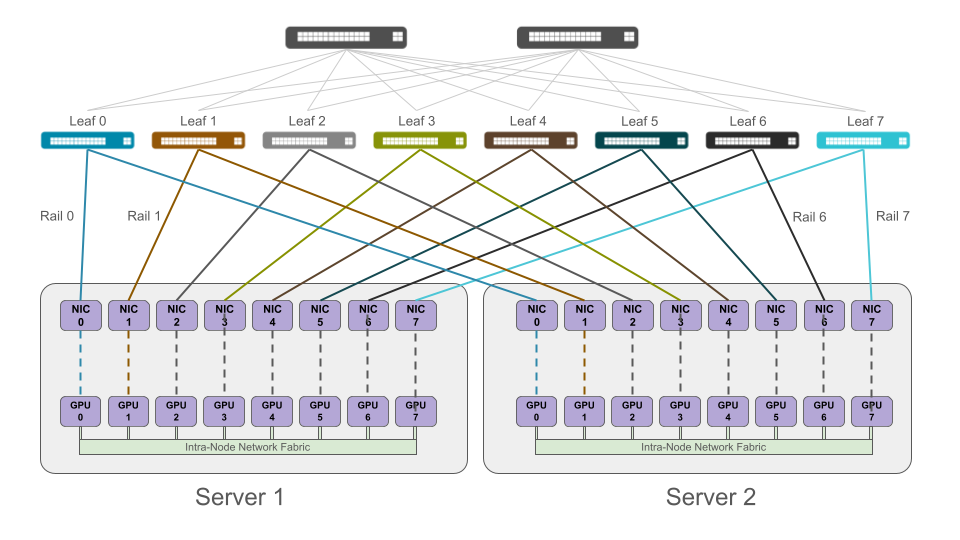
What a Rail Actually Is
The term “rail” is sometimes misunderstood. A rail isn’t a separate topology or a bypass of the leaf-spine fabric. Instead, it’s a consistent mapping of endpoints to a specific network plane within a shared Clos-based fabric.
Most real implementations are multi-plane Clos fabrics in which each plane operates independently (its own failure and congestion domain) and endpoints are deterministically assigned to planes. So while traffic can still travel leaf-to-spine-to-leaf, it does it within a constrained and predictable subset of the fabric.
And most important to keep in mind is that we’re aligning application communication to network forwarding.
Determinism and Isolation
Rail optimization introduces two critical properties:
- Path alignment
- Failure and congestion isolation
Path alignment means that traffic between corresponding GPUs follows consistent network paths with predictable latency, which then reduces variability and jitter during synchronized communication.
Each rail acts as an independent failure domain which also provides a bounded congestion domain. This is especially important in RoCE environments, where congestion can propagate via PFC and head-of-line blocking can affect unrelated flows dragging an entire training job down.
(Head-of-line blocking is basically when the first packet in a queue is stalled for some reason thereby delaying the processing of subsequent packets.)
By constraining traffic, the blast radius is reduced and recovery behavior becomes more predictable – extremely important because a delay in the network can cause the entire job to revert to a previous checkpoint thereby extending training time (and cost).
Interaction with Collective Communication
The real power of rail optimization comes from how it aligns with collective communication algorithms. Libraries such as NVIDIA’s NCCL implement ring-based communication, hierarchical reduction, and topology-aware scheduling.
Rail-optimized designs allow mapping of logical communication structures (rings, trees) onto physical network rails which reduces contention between phases and interference between unrelated flows. And, in production, this also means less variability in collective completion time.
In other words, the network becomes an extension of the communication algorithm itself.
Rail-Only Networks
A newer and not widely deployed design is the rail-only network.
While rail-optimized designs still assume a near-complete connectivity and general-purpose flexibility for AI workloads, the rail-only design is a more aggressive approach, often explored in research and not deployed as extensively. Some experimental designs explore eliminating parts of the spine layer and relying more heavily on high-bandwidth intra-node fabrics such as NVSwitch for certain communication paths.
In this design, connectivity is selectively provisioned and only the GPUs that need to communicate directly are fully connected. The spine layer is eliminated, and the infrequent communication between rails traverses the very high throughput intra-node network fabric, often an NVSwitch but not always depending on the design. In other words, GPU traffic can be engineered to never exit the rails.
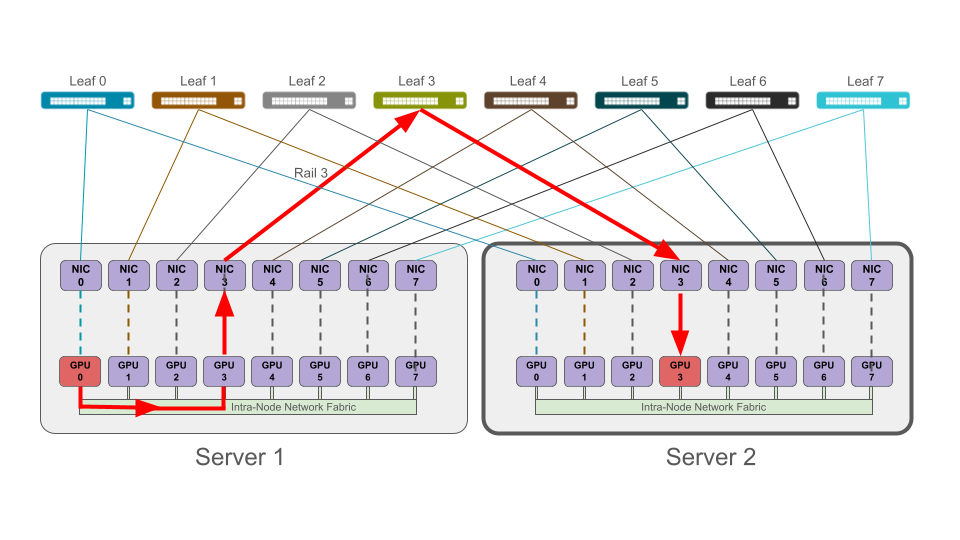
A major benefit is the cost savings from a reduction of switches and optics needed. Also, power consumption is more efficient in terms of kilowatts of power savings compared to a GPU cluster of the same size operating with a rail-optimized network. Lastly, we can also see performance improvement because even in rail-optimized networks, rails can sit idle during LLM training.
The primary limitation of rail-only designs is that we sacrifice flexibility, general-purpose usability, and an overall tolerance for workload variation. This is because rail-only designs assume that the workload is well understood and relatively stable. This design isn’t yet broadly production-proven and isn’t widely deployed.
Tradeoffs and Operational Reality
Rail-optimized architectures introduce real complexity.
First, we have reduced flexibility because the network is no longer workload-agnostic. Instead, it’s tightly coupled to AI training patterns which means changes in workload can invalidate our design assumptions.
Also, increased system-level coordination sacrifices simple, stateless ECMP. In a rail network we have to design coordination between the network design, GPU topology, and communication libraries.
Third, failure handling becomes more deliberate and less forgiving. In traditional Clos networks, failures are absorbed by path diversity. In rail-based systems, failures affect specific communication paths and recovery depends on multi-plane redundancy and application-level resilience.
Lastly, debugging is more specialized because troubleshooting requires visibility into GPU communication patterns and correlation between network telemetry and application phases. So instead of simply finding the bad link, it becomes a matter of understanding how the workload maps onto the fabric end-to-end.
Where This Is Going
Rail-optimized networking reflects a broader shift from general-purpose infrastructure to a workload-specific design. We’re seeing co-design between compute, network, and software, topology decisions driven by application behavior, and a tighter integration between orchestration, scheduling, and also transport.
Clos isn’t going away, but it is evolving from a neutral transport into a structured foundation for distributed systems like we see in AI training. It’s also important to remember that Clos designs are still the correct underlying topology even in these systems, so the problem is not the Clos architecture itself, but treating it as a neutral, workload-agnostic fabric in environments where traffic is anything but neutral.
At a small scale, the network is just a transport, but in hyperscale AI training environments, the network becomes part of the distributed system itself. Rail-optimized architectures make that definite not by replacing Clos networks, but by constraining and structuring it to match how AI training workloads actually behave.
In other words, in large-scale AI systems, the network is no longer an independent transport layer. It’s part of the compute system itself, and its behavior directly shapes how computation for AI training jobs is executed. The rail-optimized network maps how the application communicates to how the network forwards traffic.
Thanks,
Phil


Hey Phil, thanks for taking the time to write this up. It’s nice to see public articles with useful information.
In your rail-only image, it’s worth pointing out that NCCL (and I believe RCCL) has not implemented what’s known as receive-side PXN yet. This means that all PXN operations happen on the sending nodes. So your image is slightly off in that the PXN operation will happen at the origin host to swap ranks from 0 to 3.
This matters primarily in that the sending node doesn’t actually validate that the remote rank is reachable before the job kicks off. NCCL just makes assumptions about ranks based on the topology that’s presented to it (simple gpu rank numbering). So if there is a failure that makes rail3 not have connectivity to gpu3 on the remote host, this traffic will be dropped rather than sent via rail1 and then PXN’ed over to gpu3 at the host side. I believe that this is one of the reasons rail-isolated/rail-only hasn’t really been seen much. It’s a shame, because rail-isolated has major scale advantages, especially when we start talking about a leaf-spine network dedicated to a single rail (or multiplanar where you could have a leaf/spine per-rail, per-plane; each plane effectively splitting the nic itself and connecting to isolated fabrics per plane). In practice, rail-optimized (even with oversubscription between leaf and spine) to allow for some cross-rail traffic could help mitigate this to an extent.
https://github.com/NVIDIA/nccl/issues/1995
LikeLiked by 1 person
Thank you for the explanation, Tyler! I didn’t know that, so that’s extremely helpful for a deeper understanding. Fixed the image!
LikeLike