Sometimes political, financial, or logistical hurdles determine how we solve networking problems. In these tricky situations we may not be able to solve the problem the way we’d prefer, but we still need to solve the problem.
In this post I’m going to look at how we can solve a WAN failover scenario when we have a default route learned from both of our service providers and a reachability problem via our primary ISP.
In this scenario, ISP-A has been having internal problems several hops into their cloud from our edge. This means that though the BGP session with our primary ISP never drops and therefore no failover action occurs, routing to the internet still breaks.
We need to configure ISP failover using only what we have. We aren’t able to take a full feed from our ISPs, and our solution can’t require manual intervention.
For this scenario, we have the following limitations:
- We are using a single router connected to two ISPs for internet connectivity
- ISP-A must be primary
- ISP-B must take over if ISP-A fails even if the failure is several hops upstream
- Traffic flow must revert back to ISP-A with no manual intervention
- Both ISPs are advertising a default route which cannot be changed
- Failover to ISP-B and fail-back to ISP-A should each take as little time as possible
For our topology, we have the following considerations:
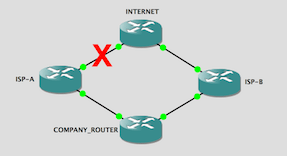
- INTERNET simulates the public internet beyond our ISP’s PE devices. It advertises several loopback addresses via BGP to ISP-A and ISP-B
- Both ISPs peer with COMPANY_ROUTER, and both advertise only a default route to us
- LAN represents our inside network and has a static route to the internet via COMPANY_ROUTER which has a static route for the inside networks behind LAN
This is our topology:

Since we’re learning the same default route from both providers, the first thing we need to do on COMPANY_ROUTER is make sure we prefer ISP-A. The default local preference in BGP is 100, and since higher values are preferred, all we need to do is make sure the local preference for routes learned from ISP-B is lower.
route-map CHANGE_LOCAL_PREF permit 10 set local-preference 80
Apply this route-map inbound on the neighbor statement for ISP-B.
router bgp 100 neighbor 10.10.13.2 route-map CHANGE_LOCAL_PREF in
Now we need to prepend additional autonomous systems to our advertisement to ISP-B so that return traffic from the internet prefers the path to us through ISP-A.
route-map PREPEND_AS permit 10 set as-path prepend 100 100 100
Make sure to apply this route-map outbound on the neighbor statement for ISP-B.
router bgp 100 neighbor 10.10.13.2 route-map PREPEND_AS out
This is enough configuration to prefer ISP-A and to have failover to ISP-B if the BGP session with ISP-A fails. But this kind of failover is triggered by the loss of the BGP session which would be caused by our router and the ISP router not being able to communicate with each other for any reason.
Our situation is a little different, though. When ISP-A has problems several hops away from us into their cloud, we don’t lose our session with ISP-A’s router. COMPANY_ROUTER and ISP-A are both up and communicating, so despite there being a routing problem just beyond ISP-A’s PE router, we keep it as the next hop for our default route. As far as COMPANY_ROUTER is concerned, nothing is wrong.
There are a few ways to accommodate this type of failure, but remember that there can be no manual intervention and we can’t ask our ISPs for a full feed.
One method that worked in my lab setup was to tie a track object to an EEM script in order to shutdown the neighbor and force the session to drop. My first thought was to shut down the interface itself (which would work), but I couldn’t think of the logic to bring the interface back up automatically. Shutting down the neighbor keeps the interface up and allows me to bring back the neighbor automatically.
We start by configuring the IP SLA and track object. For this lab I’m pinging one of the loopbacks on INTERNET, but in production you can ping the last hop in your provider’s cloud before it goes to the next ISP or something reliable on the internet that you trust. Notice that my source is the interface on COMPANY_ROUTER connected to ISP-A.
ip sla 1 icmp-echo 2.2.2.2 source-ip 10.10.12.1 frequency 5 ip sla schedule 1 life forever start-time now ip sla 10 icmp-echo 2.2.2.2 source-ip 10.10.12.1 frequency 5 ip sla schedule 10 start-time now
Now we configure the script to shut down the peer.
event manager applet SHUT_ISP-A_PEER event track 1 state down action 0 cli command "enable" action 1 cli command "conf t" action 2 cli command "router bgp 100" action 3 cli command "neighbor 10.10.12.2 remote-as 200 shutdown" action 4 cli command "end"
This EEM script tracks reachability to 2.2.2.2 through ISP-A. If reachability is lost because of an upstream ISP issue, the script runs through the commands above to shut down the neighbor forcing a failover to ISP-B.
To revert back to ISP-A, the inverse action is required in a second EEM script.
event manager applet RE_ENABLE_ISP-A_PEER event track 1 state up action 0 cli command "enable" action 1 cli command "conf t" action 2 cli command "router bgp 100" action 3 cli command "no neighbor 10.10.12.2 shutdown" action 4 cli command "end"
You can also add a log message as a fifth action, but for this example I’ve kept things very simple.
When we simulate the upstream outage by shutting down interface gig 0/0 on ISP-A (the far end from us), the track object goes to a down state triggering the script and failing over our default route to ISP-B.
But we’re not done just yet. After we fail to ISP-B, the pings to our tracked IP address will succeed again causing us to revert back to ISP-A. To make sure we’re checking for reachability through ISP-A’s local cloud, we can use a simple static route to our tracked IP address with the next hop of ISP-A.
ip route 2.2.2.2 255.255.255.255 10.10.12.2
Now, even when we’ve failed over to ISP-B, COMPANY_ROUTER will still be checking for reachability through ISP-A.
When the issues with upstream routing are resolved, the pings to the track object through ISP-A will succeed triggering the second EEM script to revert to ISP-A.
In order to speed up slow convergence after the failover you can adjust your BGP timers on a per-neighbor basis or globally on the BGP process. This is based on your needs and your overall topology.
Since this is a very simple topology using only a default from each ISP, I reduced the timers global timers a lot. How much is too much is debatable. It’s something to experiment with and possibly talk to your ISPs about. Just remember that applying new timers requires a hard reset of the sessions causing a brief outage.
A better way to do this would be to take a full feed from our ISPs and configure BGP accordingly, but in this case that wasn’t an option. If you have other ideas of how we could have solved this scenario, please let me know in the comments or tweet them out. One thing I’ve learned over the years is that there’s often more than one right way to do something!

