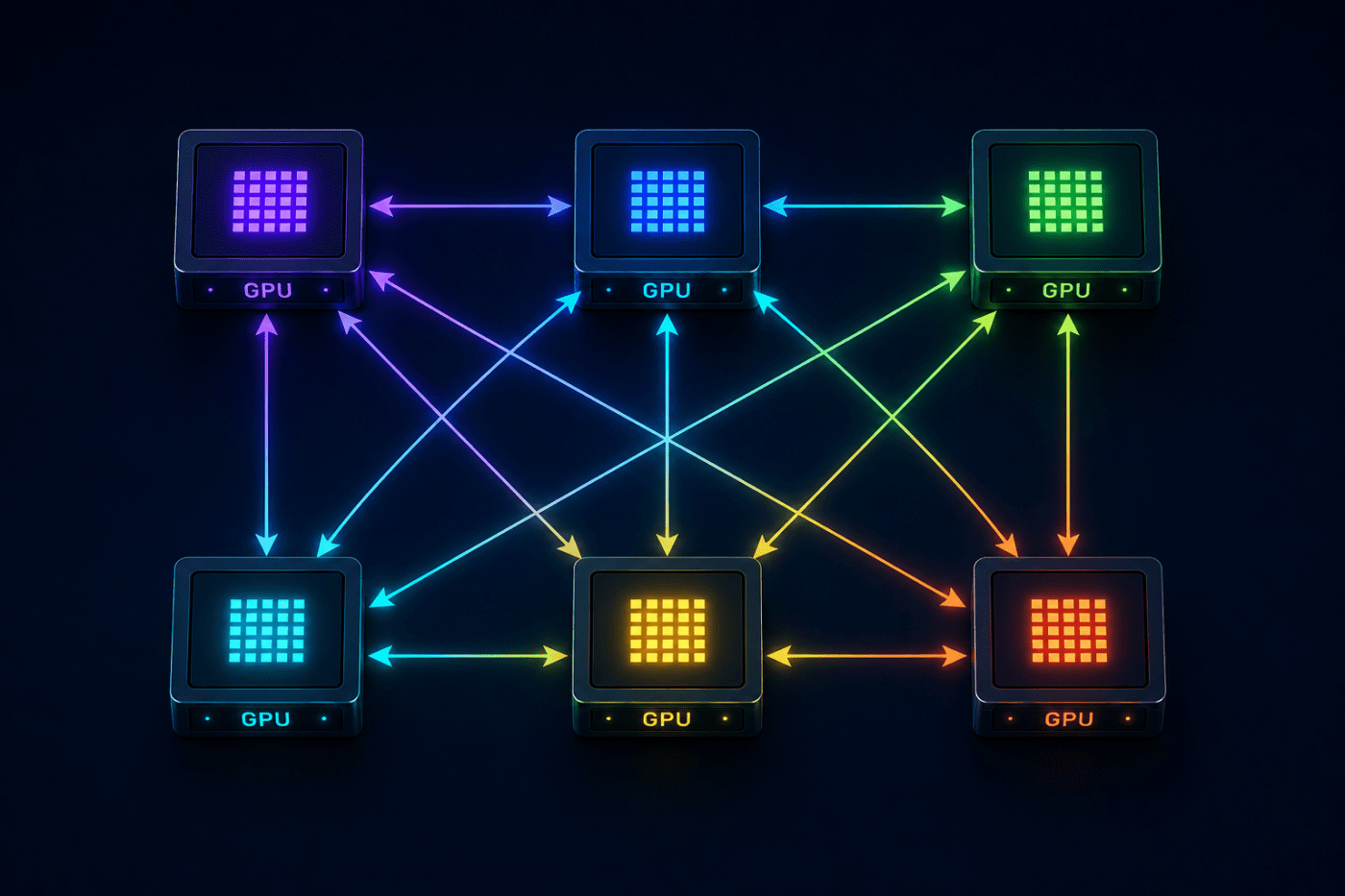
For decades, network architects designed data center networks primarily around application and storage traffic. Whether supporting enterprise applications, web services, virtualization platforms, or cloud-native workloads, the network was the transport mechanism connecting users, applications, and data.
Traffic patterns were characterized by north-south communication flows, predictable east-west application exchanges, and a relatively loose coupling between compute and network performance. High-performance computing environments differed somewhat by emphasizing ultra-high bandwidth, low latency, and efficient inter-node communication for distributed workloads. However, modern AI infrastructure introduces a fundamentally different model.
Modern AI training clusters consist of hundreds, thousands, and even tens of thousands of accelerators operating as a single distributed computing system. Rather than running independent workloads, these accelerators continuously exchange gradients, parameters, activations, embeddings, and synchronization information throughout training and inference.
(An accelerator is any specialized compute device like a GPU or TPU that’s optimized for parallel numerical operations such as matrix multiplication, tensor operations, and vector arithmetic.)
As a result, the dominant traffic within an AI cluster isn’t traditional application traffic. Instead, it’s communication traffic generated by the distributed computing system itself. These communication exchanges are known as collective communications.
Collective communications have existed for decades in the high-performance computing world. However, the scale of modern AI systems has brought them from a specialized HPC concept to a primary driver of data center network architecture.
Today, network topology, congestion management, load balancing, optical infrastructure, cabling density, and even physical rack placement (seriously) are increasingly optimized around collective communication performance. Collective operations explain why AI networks require exceptionally high bisection bandwidth, why east-west traffic dominates fabric utilization, and why small network ineffiencies can translate into millions of dollars of lost accelerator productivity.
The Challenge of One Model but Many GPUs
To understand collective communications traffic patterns, it’s important to understand why they exist in the first place.
The largest AI models in production today contain hundreds of billions or even trillions of parameters. Training datasets often encompass trillions of tokens, and the computational requirements for these types of workloads are far beyond the capabilities of any single accelerator. Because of that, AI systems distribute both computation and memory across large numbers of GPUs.
A single model training job might span hundreds or thousands of accelerators with parts of the model distributed across multiple networked devices. Datasets are distributed among workers, and the intermediate computational results are exchanged continuously throughout the training process.
(A worker in this context is just a single server with a GPU that performs a small part the training workload.)
For networking especially, this introduces a huge challenge. While the workload is distributed, the model itself has to behave like a single, coherent system. The distributed system has to maintain sufficient consistency of model state and intermediate computational results so that training can progress correctly. This includes gradients that have to be synchronized and parameters that have to be shared. Also, activations have to be exchanged and the intermediate results must be aggregated and redistributed. In other words, this kind of massive distribution creates a network communication problem, and collective communications are the mechanisms used to solve it.
What do Collective Communications do?
At a high level, collective communication operations allow groups of accelerators to exchange, aggregate, synchronize, and distribute information very efficiently. Instead of treating communication as a series of independent point-to-point flows, collective operations coordinate communication across entire groups of participants simultaneously.
That means the network is no longer merely transporting application traffic. Instead, the network is an active participant in the computational process itself. As John Gage of Sun Microsystems famously said in 1984, “the network is the computer.”
The Most Important Collective Communication Operations
Although multiple collective operations exist (many of which we won’t cover here), a relatively small number are used for the majority of communication in modern AI clusters. The most commonly used framework is the NVIDIA Collective Communications Library (NCCL).
Broadcast
Broadcast operations distribute data from a single source to every participant in a communication group.
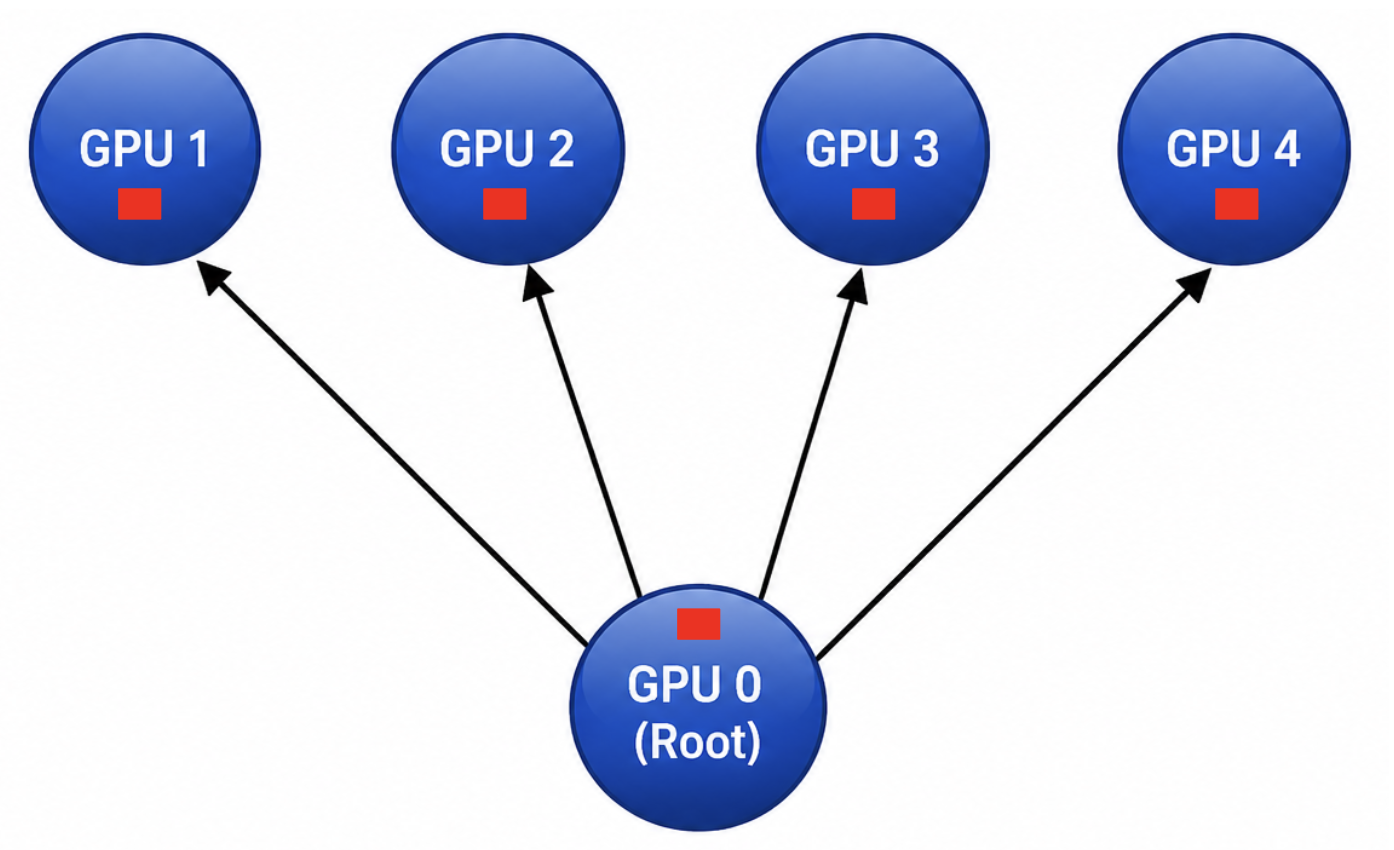
A simple example is when one GPU distributes model parameters or configuration information from one process to many worker GPUs.
In the image on the left, you can see that GPU 0 (the root) sends the same data to all other GPUs.
In theory, broadcast represents a one-to-many communication pattern. So as cluster size increases, efficient implementation of broadcast traffic becomes extremely important since replicating traffic individually to every destination becomes extremely expensive at scale.
Gather
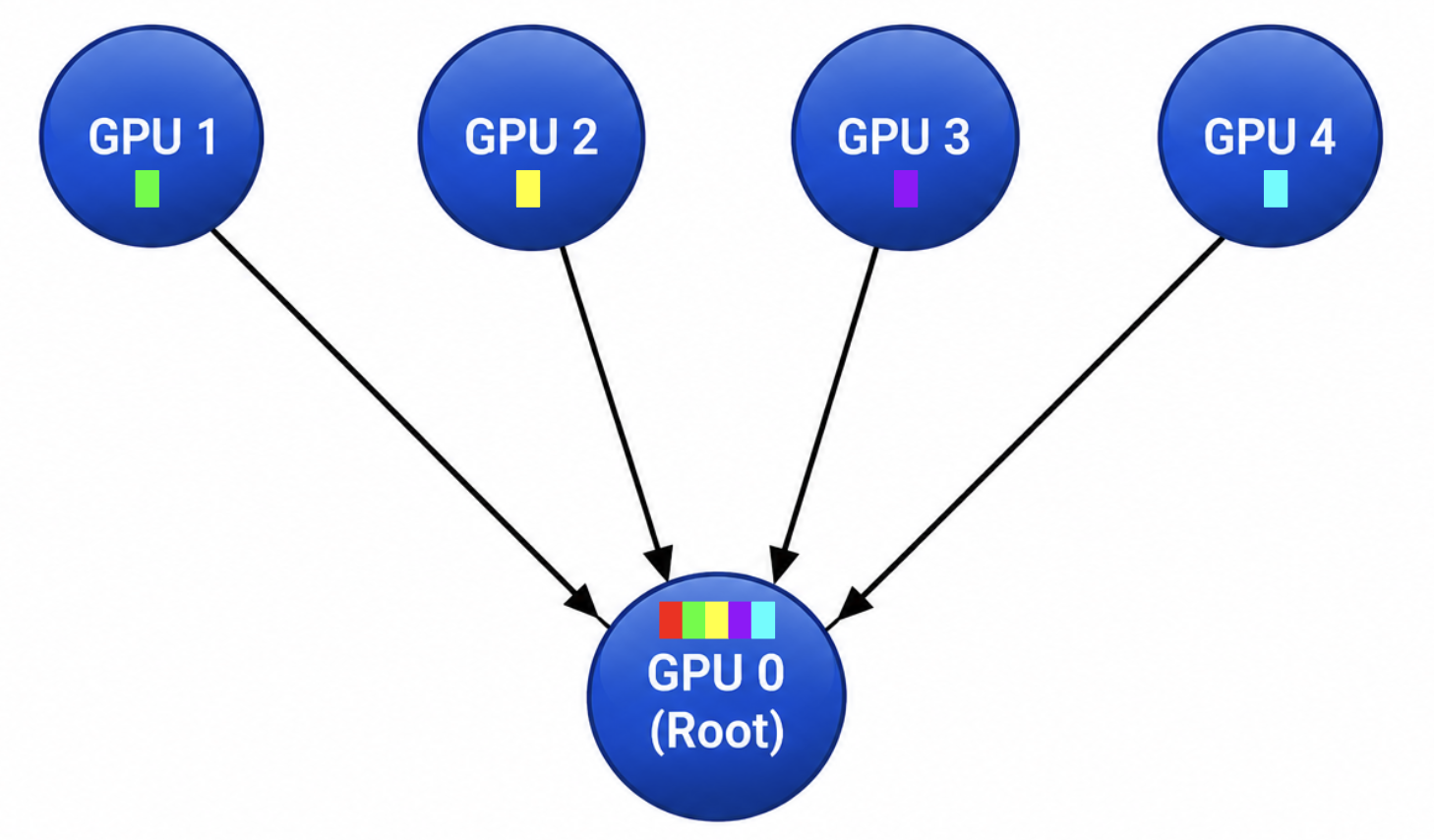
Gather operations perform the inverse of broadcast.
In the image on the right you can see GPUs 1-4 send there individual data to GPU 0 to be collected.
Basically, in gather operations, multiple participants send information to a single destination where the results are collected. Gather operations often appear in data aggregation and coordination activities within AI workloads.
AllGather
AllGather goes beyond Gather. In an All-Gather operation, each participant contributes a portion of data, and the final result is distributed back to every participant. For example, imagine eight GPUs each store one-eighth of a tensor. In an AllGather operation, all eight GPUs will receive the information they need to generate the complete tensor. In actual practice, each GPU usually sends data to a subset of neighbors during each phase.
In the image below, you can see how the result is that every GPU receives the complete dataset assembled from all participants.
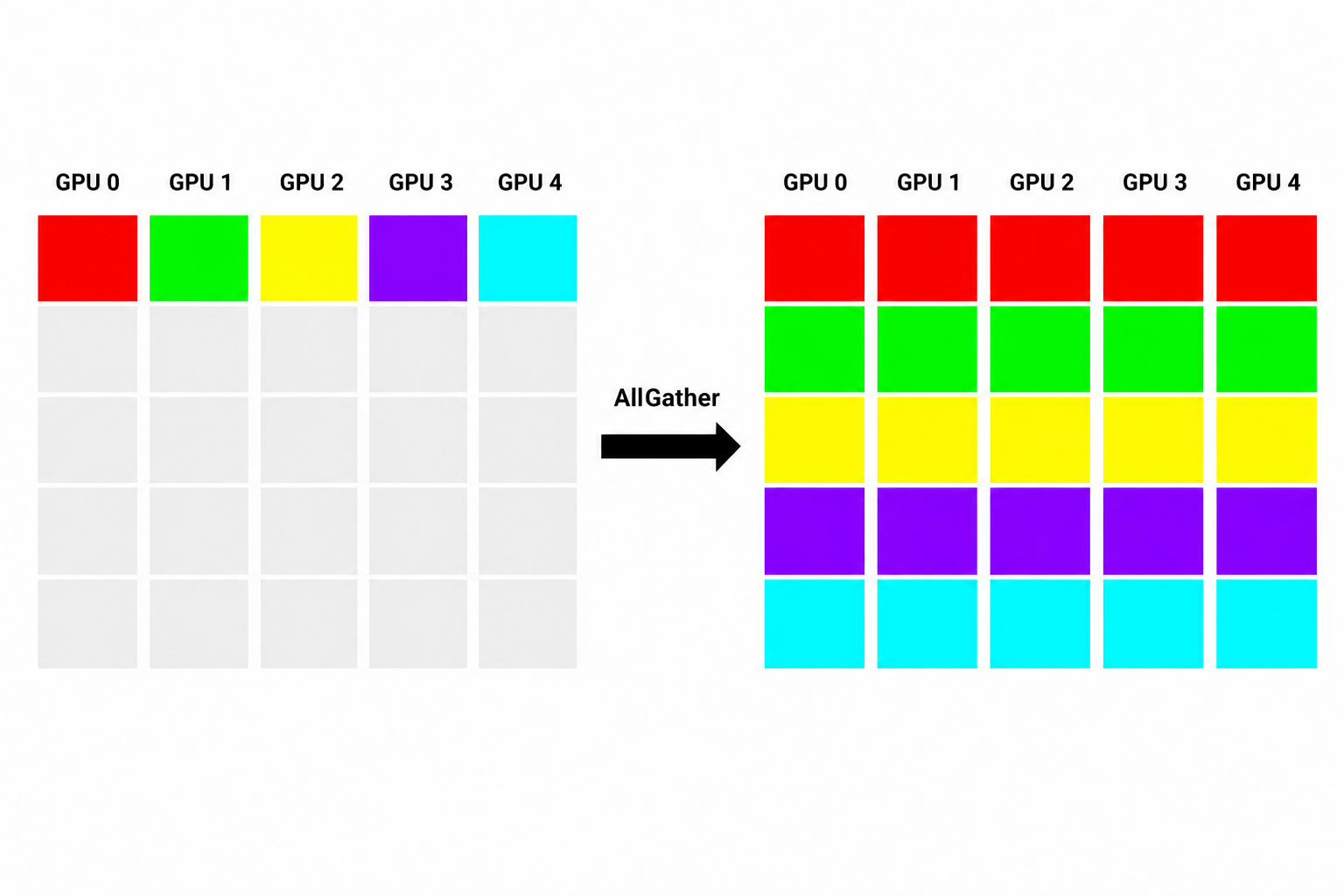
AllGather operations are especially common in tensor-parallel training architectures and very important in large-scale inference deployments.
Reduce
Reduce operations aggregate information from multiple nodes using mathematical functions such as sum, minimum, maximum, or averaging. So instead of distributing the result in a broadcast, the reduced value is delivered to a specific, designated participant.
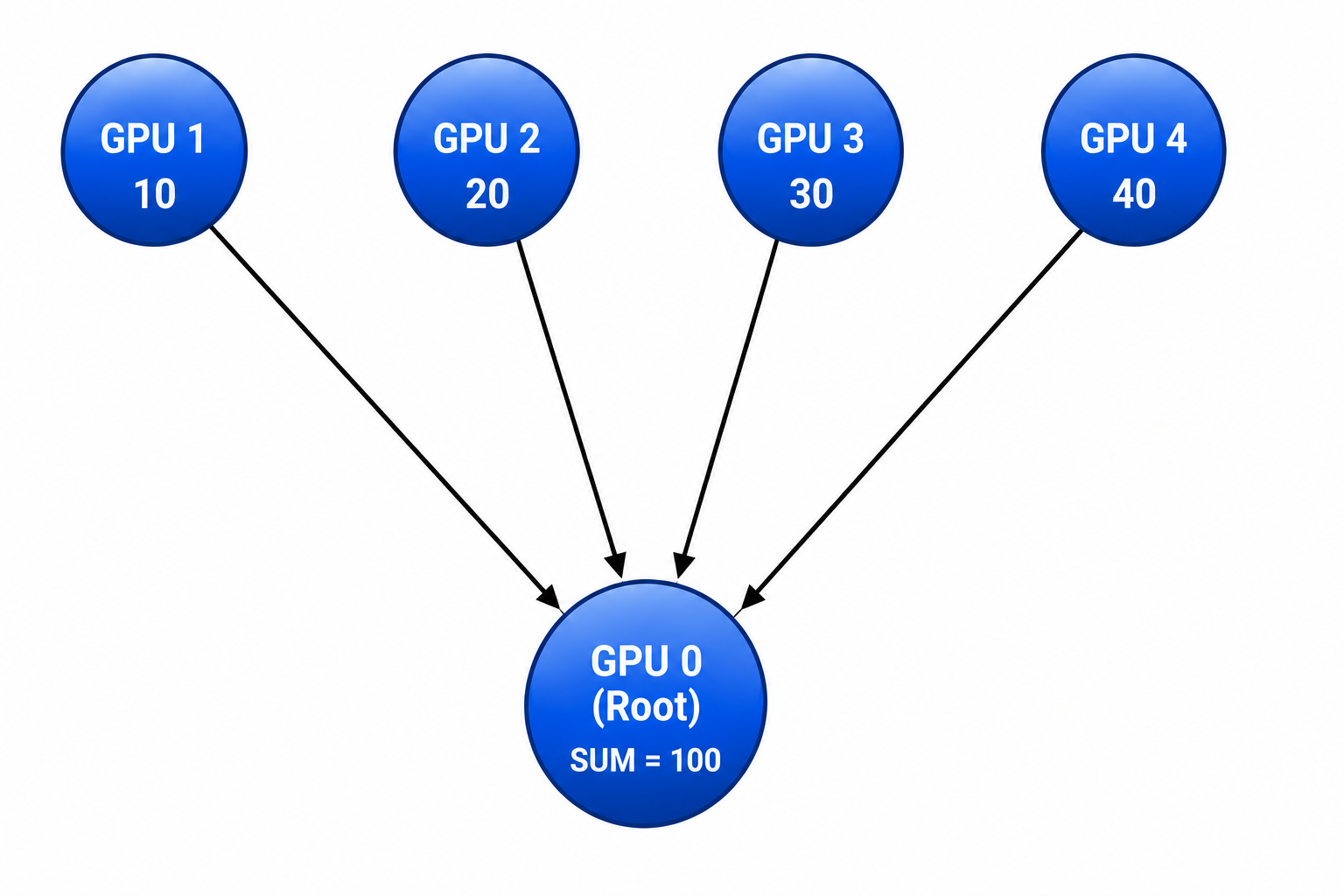
In this simple example image on the left, you can see that each GPU performed its own individual calculation (in parallel with the other GPUs), and in a reduce operation sends that data to the designated GPU to be, in the case, added together.
The actual calculation can be any variety of operations, and the individual reduce operation itself is normally a part of a series of other, more complex operations such as ReduceScatter or AllReduce.
AllReduce
Among all collective communication operations, AllReduce is probably the most important in distributed AI training. Every participant contributes information to a reduction operation. Then, the resulting aggregate value is distributed back to every participant.
In the image below you can see each GPU contributes data to a distributed reduction operation with the resulting reduced value then being distributed to every participant.
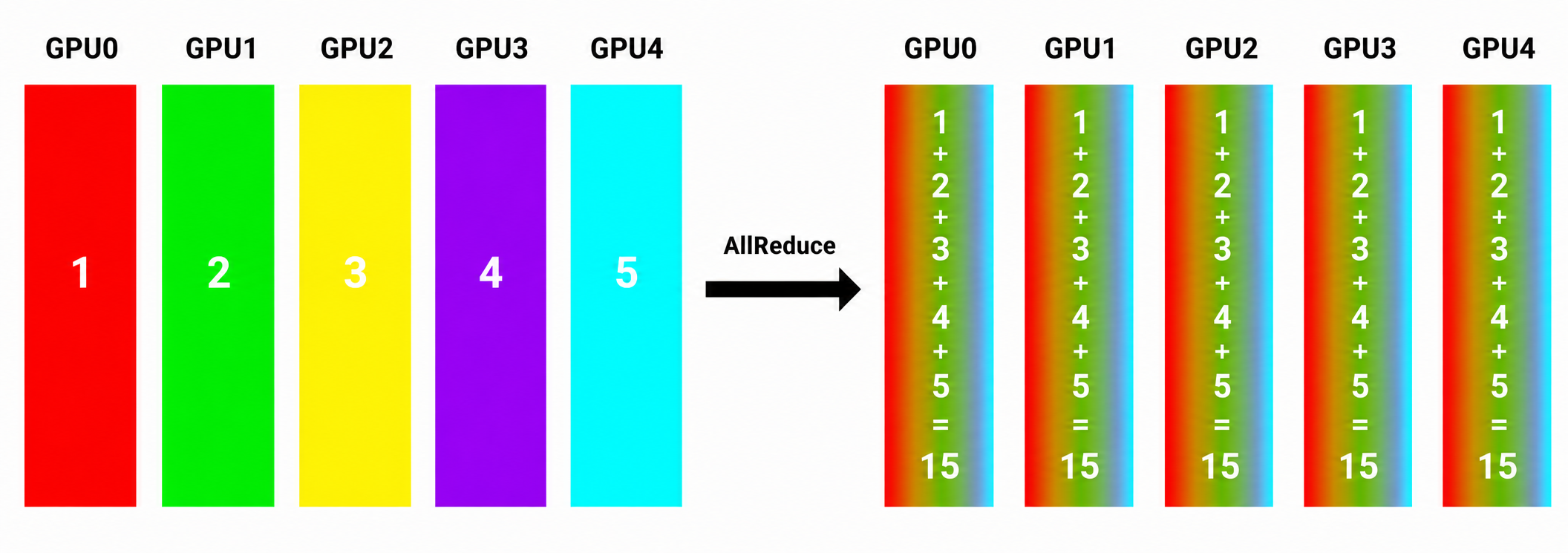
A classic example of AllReduce is gradient synchronization within data-parallel training. Each GPU independently computes gradients from its assigned training data, but before training can continue, those gradients have to be combined and synchronized across all the participating workers.
AllReduce performs this synchronization, and therefore, the efficiency of All-Reduce usually becomes a primary factor of the overall training performance. And specifically in the context of networking, as model sizes and cluster scales increase, AllReduce traffic often becomes one of the dominant consumers of network bandwidth.
AlltoAll
At a high level, AlltoAll is when every participating GPU sends data to every other participating GPU. AlltoAll is one of the most demanding and bandwidth-intensive collective communication patterns in modern AI training.
There’s a lot going on in an AlltoAll operation, which you can see in the image below. Every GPU sends a unique piece of data to every other GPU and likewise receives a unique piece of data from every other GPU.
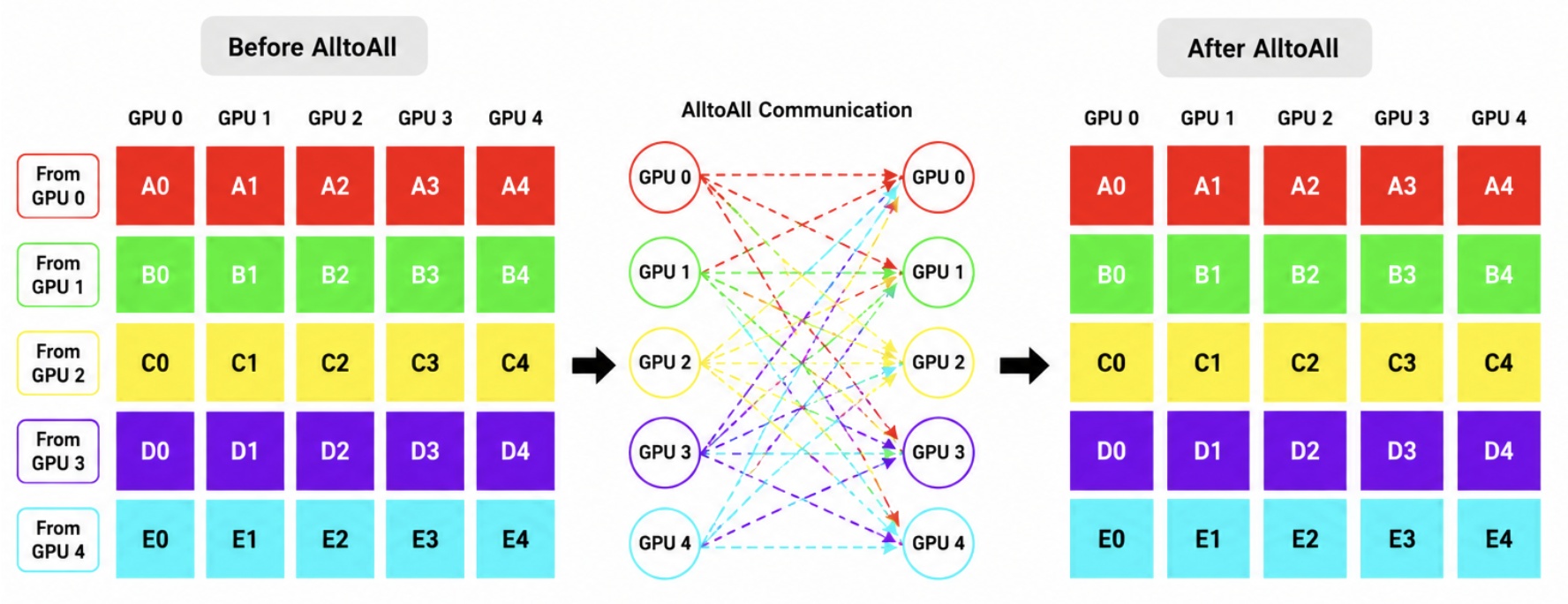
In this type of traffic pattern, there is no central destination. Every endpoint is simultaneously a sender and receiver, and the result is a massive burst of east-west traffic. We see this frequently in MoE (Mixture of Experts) implementations.
Why Collective Communications Dominate AI Data Center Traffic
So why are collective communications so dominant in AI data center networks? Simply put, every AI training iteration usually requires multiple collective operations involving thousands of accelerators, and these operations occur repeatedly throughout the duration of a training job which could take days, weeks, or months. The result is huge volumes of east-west traffic.
During large-scale model training, the overwhelming majority of network traffic often remains entirely within the cluster itself. Traffic generated by users, storage systems, and external applications represents only a small fraction of total network utilization.
This is why AI networking discussions focus on metrics such as:
- Bisection bandwidth
- Fabric utilization
- Latency consistency
- Congestion management
- Load balancing efficiency
- Collective completion time
Therefore, in AI data centers, the network isn’t being optimized for application delivery but for collective communication performance.
The Relationship Between Parallelism and Network Traffic
Something important to note is that different forms of AI model parallelism generate different communication patterns.
For example, data parallelism relies heavily on AllReduce operations for gradient synchronization, while tensor parallelism generates frequent AllGather and ReduceScatter operations as tensors are partitioned across many accelerators. Pipeline parallelism generates continuous exchanges of activations between computational stages, and Mixture-of-Experts architectures create extremely dynamic network traffic patterns as tokens are routed among distributed expert networks.
The common theme is that as computation becomes more distributed, communication requirements increase accordingly. It also means that understanding exactly what sort of AI training activity is occurring is critical in predicting traffic patterns and designing an appropriately optimized network.
In AI data centers at sufficient scale, collective communications become the dominant workload running on the network and are ultimately what transform thousands of individual accelerators into a single distributed computing system. The future of AI networking will be defined not simply by faster speeds and feeds, but by how effectively networks can support the collective communication operations that drive distributed AI training and inference.
Thanks,
Phil


Leave a comment